
Baseline
For the code and guide of the baseline system, please refer to Github link
For more description of the baseline system, please refer to the following two papers:
Data Preparation
As shown in the Data section, we performed data cleaning on the raw audio data and simulated 6-channel far-field audio using the cleaned near-field speech.
System Architecture
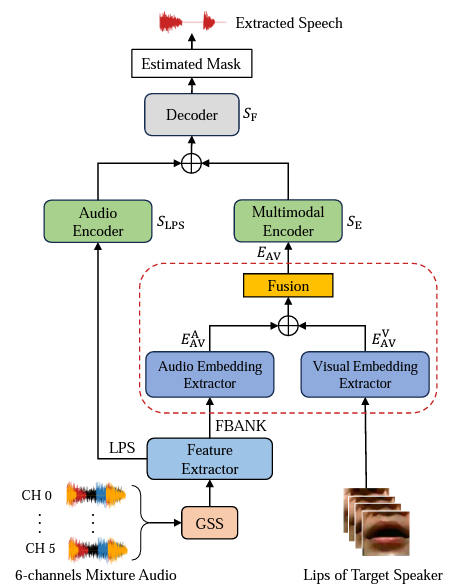
As shown in Figure 1, first, we used the oracle diarization results to conduct guided source separation (GSS) on 6-channels mixture audio to initially mitigate the impact of the overlapping speech. Then, we use our recent work - the multimodal embedding aware speech enhancement (MEASE) model to futher extract the speech of the target speaker. The MEASE model comprises a multimodal embedding extractor (in red dashed box) and an embedding-aware enhancement network. For more details, please refer to the two papers above.
Training Process
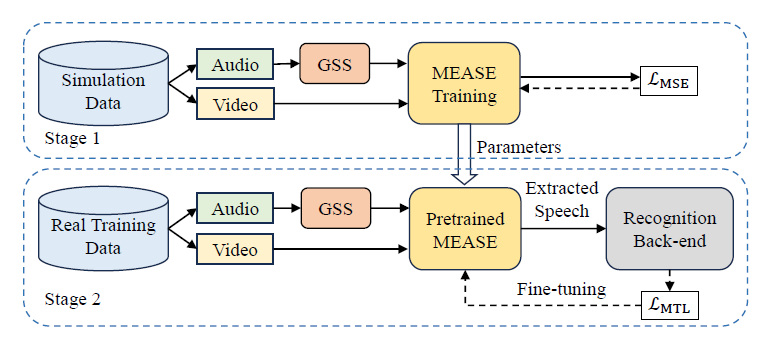
As shown in Figure 2, the training process of the baseline system encompasses two stages. Firstly, we trained the MEASE model using the simulated data with MSE as the loss function. In the second stage, we fine-tuned the pre-trained MEASE model using the recognition back-end. Furthermore, to mitigate the issue of mismatch between simulated data and real-world scenarios, we utilized the real far-field data from the training set in the second stage. Because we require that the parameters of the back-end system cannot be changed, we freeze the recognition model and only use the loss returned by it.
Back-end ASR Testing
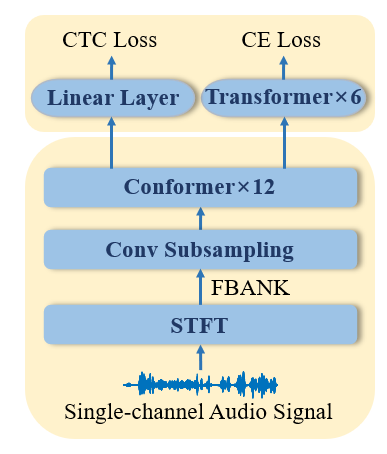
The backend ASR model is based on this following paper:
To better investigate the role of the AVTSE system, focusing on the enhancements brought by audio improvements, we use the audio-only part of that paper, as shown in figure 3. We have given the code and the pre-trained parameters for the ASR model, which you can find in the github link above. You can test the extracted speech directly. In addition, you can also use different methods to use the back-end system to finetune the front-end AVTSE system just like the baseline system, but you must ensure that the back-end system parameters do not change.
Baseline Results
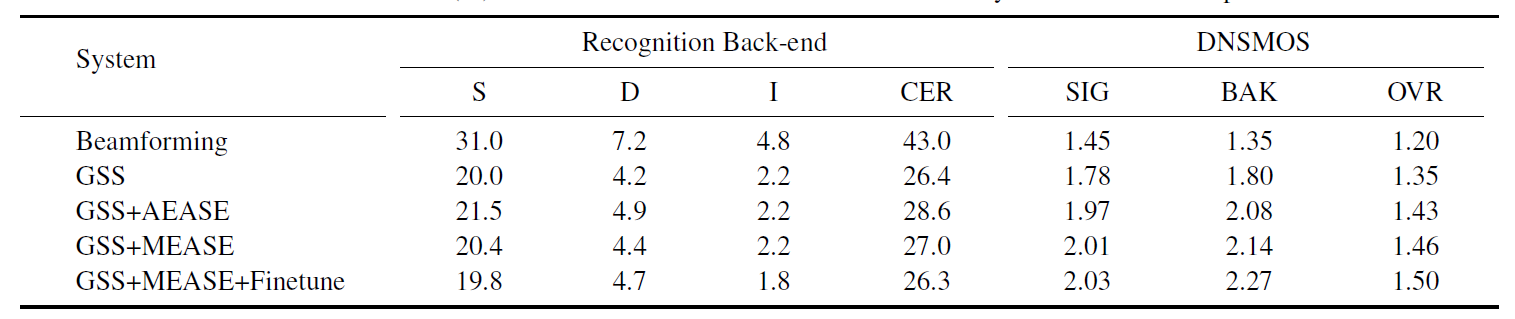
Table 1 shows the results of different front-end systems in the speech recognition evaluation metric and DNSMOS P.835. It is worth noting that we only use the recognition results as the evaluation indicators. DNSMOS is only used as a reference to study changes in speech quality. The final baseline result is the CER of 26.3. The baseline results of the evaluation set will be given after the evaluation set is released.