
Instructions
Audio-visual target speaker extraction (AVTSE) aims to extract the target speaker’s speech from mixtures containing various speakers and background noise using audio and video data. In MISP 2023 challenge, we will explore the impact of the front-end AVTSE system on the back-end recognition system. In the development and evaluation stage, we only use middle-field video and 6-channels far-field audio. In addition, we will provide speaker related speech timestamps, which participants can use to segment the audio.
Evaluation
The ultimate goal of studying the front-end speech processing system is to improve the performance of the back-end system. To explore the impact of AVTSE on the back-end system, we will use an ASR model to decode the extracted audio, and calculate character error rate (CER) as the evaluation metric.
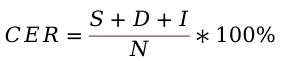
Where, S, D, and I represent the number of substitutions, deletions, and insertions, respectively. N is the number of characters in ground truth. The lower CER value (with 0 being a perfect score), the better the recognition performance, which means the better the performance of AVTSE.
To enable participants to develop and adjust their AVTSE systems, we will provide a pre-trained ASR model, which is the latest research of our team. To better investigate the role of the AVTSE system, focusing on the enhancements brought by audio improvements, we only use the audio-only ASR part of paper.
If you find the above system helpful, please cite: @inproceedings{dai2023improving, author={Dai, Yusheng and Chen, Hang and Du, Jun and Ding, Xiaofei and Ding, Ning and Jiang, Feijun and Lee, Chin-Hui}, booktitle={2023 IEEE International Conference on Multimedia and Expo (ICME)}, title={Improving Audio-Visual Speech Recognition by Lip-Subword Correlation Based Visual Pre-training and Cross-Modal Fusion Encoder}, year={2023}, volume={}, number={}, pages={2627--2632}, doi={10.1109/ICME55011.2023.00447} }
We will provide the code and the pre-trained model parameters of the ASR model. In the development stage of the MISP 2023 challenge, participants can independently decode the extracted speech from AVTSE and calculate the CER to evaluate the performance. In the evaluation stage, to compare the performance of the AVTSE system more fairly, we do not allow participants to adjust the ASR model to obtain unfair results. Therefore, participants need to provide us with the extracted speech, and we will decode and calculate the CER for ranking. In addition, we will use the DNSMOS as a reference to explore the relationship between listening and back-end tasks.
Guidelines
Can I use extra audio/video/text data?
We will open two rankings based on whether external data, apart from the MISP dataset, has been utilized. However, it is worth noting that we will only submit the ranking which is without using them to ICASSP SPGC. This is because we encourage technological innovation, rather than relying on large amounts of data to train models.
If participants use additional data, they should follow the following rules:
- The used external resource is clearly referenced and freely accessible to any other research group worldwide. External data refers to public datasets or trained models. The data must be public and freely available.
- The list of external data sources used in training must be clearly indicated in the technical report.
- Participants inform the organizers in advance about such data sources, so that all competitors know about them and have an equal opportunity to use them. Please send an email to the track coordinators; we will update the list of external datasets on the web page accordingly. Once the evaluation set is published, the list of allowed external data resources is locked (no further external sources allowed).
We hope participants will pay more attention to technological innovation, especially novel model architectures, instead of relying on using more data. This is not a pure competition, but a “scientific” challenge activity.
Can I use a system different from that in the official baseline pipeline?
There is no limitation on AVTSE model structure and model training technology used by participants. You are entirely free in the development of your system. In particular, you can:
- use the single-channel or multi-channel audio data
- use other video pre-processing methods
- use real or simulated data
- use other simulation methods
- use other audio features and visual features
- use other post-processing methods
Which information can I use?
You can use the following annotations for training, development, and evaluation:
- the corresponding room sizes
- the corresponding configuration labels
- the corresponding speaker labels
- the start and end times of each speaker's speech
Which information shall I not use?
Manual modification of the data or the annotations (e.g., manual refinement of the utterance start and end times) is forbidden. All parameters should be tuned on the training set or the development set. Modifications of the development set are allowed, provided that its size remains unchanged and these modifications do not induce the risk of inadvertently biasing the development set toward the particular speakers or acoustic conditions in the evaluation set. For instance, enhancing the signals, applying “unbiased” transformations or automatically refining the utterance start and end times is allowed. Augmenting the development set by generating simulated data, applying biased signal transformations (e.g., systematically increasing intensity/pitch), or selecting a subset of the development set is forbidden. In case of doubt, please ask us ahead of the submission deadline.
Which results should I submit?
For every tested system, you need to submit the speech to be tested (extracted from AVTSE) in the evaluation set, and we will feed the submitted speech into the backend ASR model. Then we will display the CER results and update them on the leaderboard. In addition, all participants should submit the system report after the leaderboard freeze.