Background
Speech-enabled systems encounter performance degradation in real-world scenarios due to adverse acoustic conditions and interactions among multiple speakers. Effective front-end speech processing technology has been proven to have a significant role in improving the performance of the back-end system. In recent years, there have been several challenges organized to explore the performance of front-end technologies. However, it is worth noting that most existing challenges rely on the audio modality alone, which is running into performance plateaus. Inspired by the finding that visual cues can help human speech perception, we hope to explore more effective methods using audio and video information jointly to improve the performance of front-end technology. Therefore, the MISP 2023 Challenge focuses on audio-visual front-end technology.
For front-end speech processing, methods such as speaker diarization, blind source separation, and speech enhancement are commonly utilized to provide the subsequent backend tasks with higher-quality audio or audio information. Target Speaker extraction (TSE) is an alternative to blind source separation and speech enhancement, which can selectively isolate the target speaker’s voice from a mixture of various speakers and background noise, leveraging auxiliary cues that help identify the target. Previous psychoacoustic studies have inspired the exploration of different clues, such as spatial aids for determining the direction of the target speaker, visual prompts acquired via video of their face, and audio cues from prerecorded enrollment recordings of the speaker’s voice. Addressing the TSE problem has practical implications for various applications, such as (1) developing robust voice user interfaces and voice-controlled smart devices that respond exclusively to a particular user, (2) removal of interfering nearby speakers in teleconferencing systems, and (3) amplifying the voice of a preferred speaker with hearing aids/hearables. TSE has received much attention in recent years. For instance, it was included as a separate challenge in recent evaluation campaigns, such as the 4th and 5th Deep Noise Suppression (DNS) challenge. Previous challenges only focused on audio cues, mainly by providing prerecorded enrollment recordings of the speaker’s voice. However, these cues are challenging to obtain under real-life harsh acoustic conditions. Conversely, video cues are relatively unaffected by acoustic interference. As a result, an increasing number of researches focus on audio-visual target speaker extraction (AVTSE) utilizing video cues. Unfortunately, no publicly available benchmark currently exists for AVTSE.
How to better utilize the information of audio and video information is of great importance. In the previous MISP challenges, the effectiveness of combining audio and video has been verified on many tasks. In the ICASSP 2022 SPGC, the first MISP challenge released a large distant multi-microphone conversational Chinese audio-visual corpus and focused on audio-visual wake word spotting and audio-visual speech recognition with oracle speaker diarization. Furthermore, in the ICASSP 2023 SPGC, the second MISP challenge explored the impact of audio-visual speaker diarization on speech recognition. Many participants have proposed several novel methods to improve the performance of audio-visual speech processing systems. We have communicated with the participants and they unanimously believe that an excellent front-end system can greatly help with back-end tasks. Therefore, this year, MISP 2023 challenge focuses the problem of AVTSE, aiming to promote the development of audio-visual front-end technology and explore the impact of the front-end technology on the back-end system. We hope this is a scientific issue aimed at exploring the performance of AVTSE in real-world scenarios with high noise and reverberation.
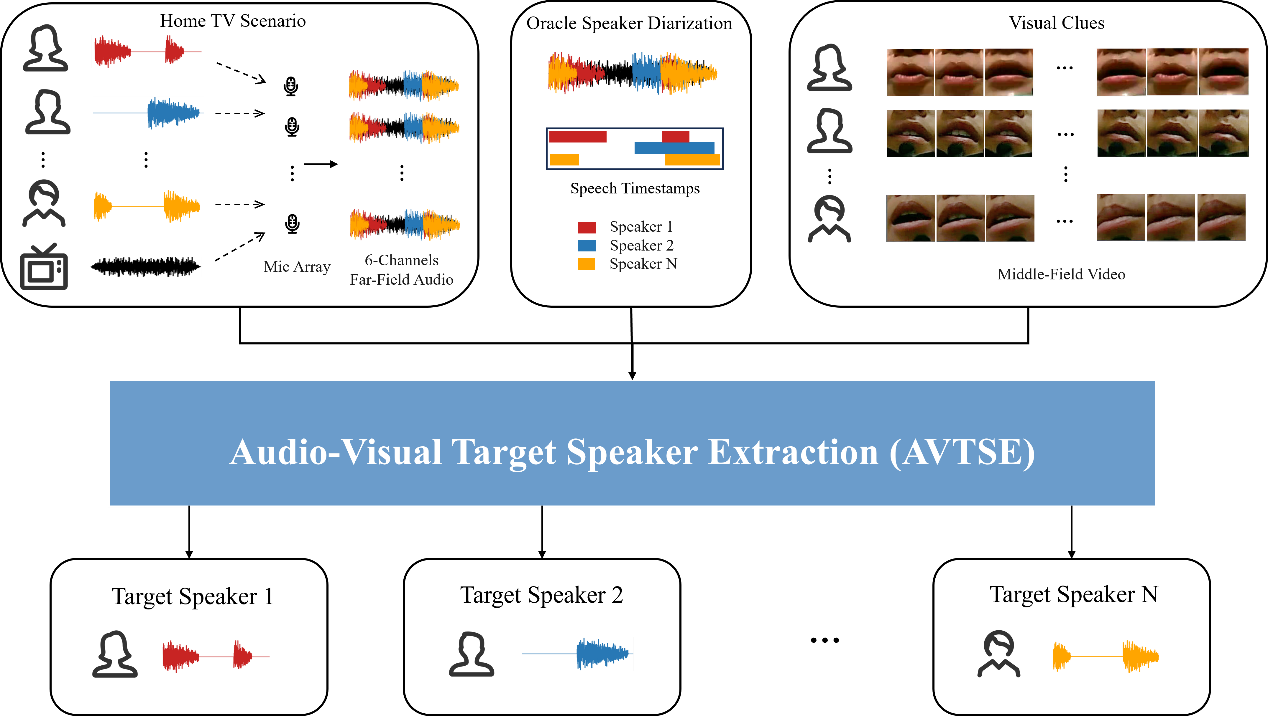
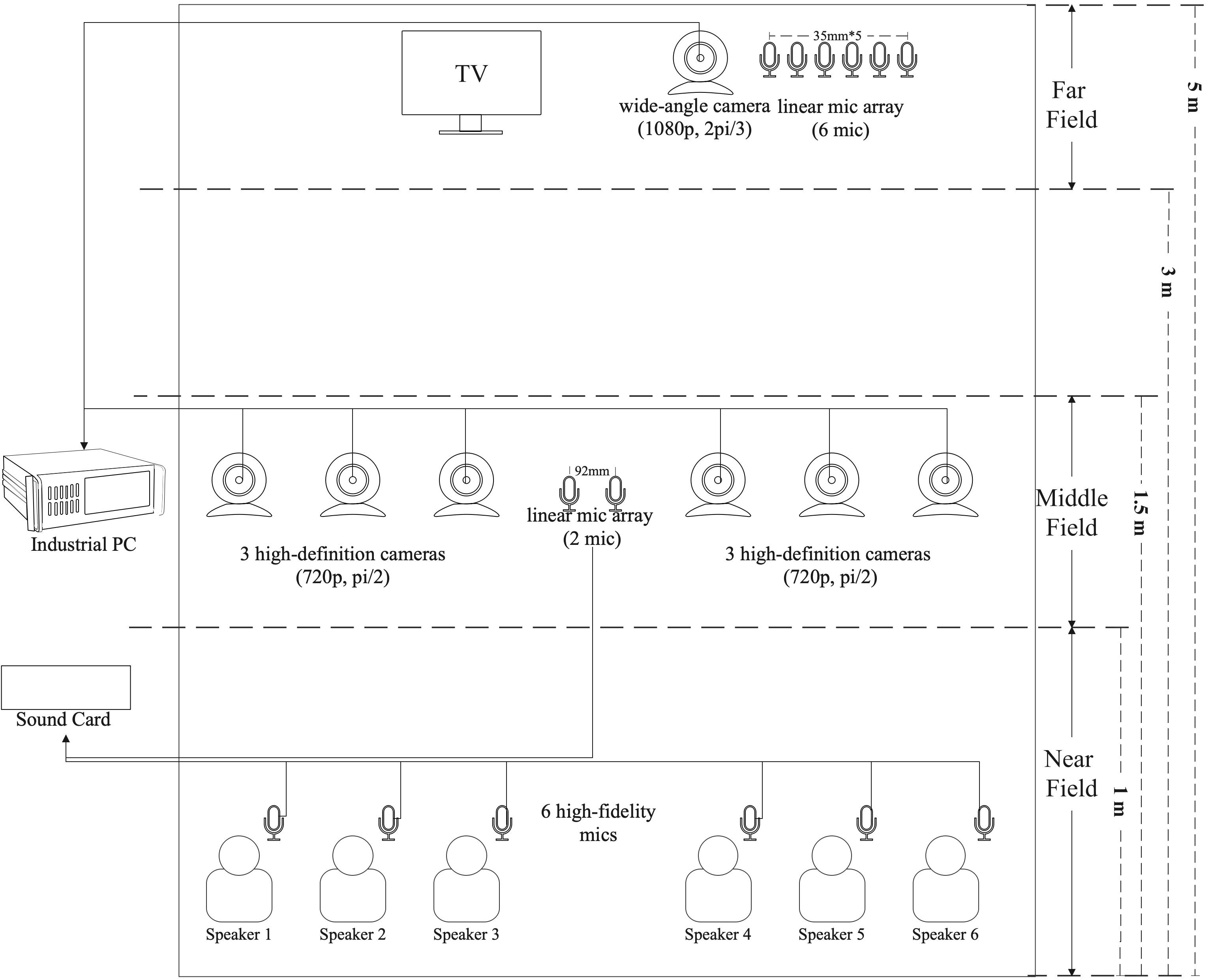
As shown in figure 1, in this challenge, we need to tackle mixture speech from complex home scenarios, which include strong background noise and high overlap ratios due to the interfering speakers. Participants need to use the 6-channels far-field audio, the middle-field video, and the oracle speaker diarization result to extract the target speaker’s speech through the AVTSE model, eliminating noise and interference from other speakers. All speakers in a session are treated as the target speakers separately.
Specifically, we target the home TV scenario, where several people chat in Chinese while watching TV in the living room. Unlike most previous audio-visual challenges, which are still limited to conducting research on the datasets under ideal condition, the MISP challenge is based on real-world scenarios. The strong background noise and reverberation, a large number of overlapping speech, and the possible blurry videos are the challenges of this audiovisual dataset. This year, different from the previous MISP dataset, we will conduct data cleansing on the training set for front-end tasks. We use the deep noise suppression mean opinion score (DNSMOS) to screen the segments with high speech quality for near-field audio. These data can be used as clean reference speech for model training by participants. To ensure complete synchronization of near-field audio and far-field audio, we will provide a data simulation script that allows participants to utilize the screened near-field speech to simulate far-field scenarios easily. We will also add some new sessions in the evaluation set, focusing on female dialogue scenarios. Our research has revealed that distinguishing speaker voices in these particular scenarios is more challenging, thus increasing the difficulty level for participants. In addition, we will provide the timestamps of each speaker’s speech, which contestants can use to segment the audio. Furthermore, a well-designed novel baseline system of AVTSE will be provided and we will also provide a pretrained model for automatic speech recognition (ASR) as the backend. Participants must develop an AVTSE system and input the extracted speech from AVTSE into the given ASR model. Please note that the ASR system is fixed and its model structure and parameters cannot be changed. Nevertheless, it is allowed to jointly optimize the front-end system and back-end ASR system while keeping the ASR model parameters unchanged. To explore the impact of the front-end technology on the back-end system, we will evaluate the performance based on the final character error rate (CER).
Through this challenge, we look forward to more academic and industrial researchers paying attention to the audio-visual front-end technology, especially AVTSE. This provides a new and important solution for solving the problem of performance degradation in complex acoustic scenes. We anticipate that this challenge will foster innovative approaches and advancements in multimodal speech processing.
The intellectual property (IP) is not transferred to the challenge organizers, i.e., if code is shared/submitted, the participants remain the owners of their code.