
In the MISP 2021 challenge, we released a large multi-microphone conversational audio-visual corpus. This corpus focus on the home-TV scenarios: 2-6 people communicating each other with TV noise in the background. The detailed scenario and recording setup can be found in the first paper. In the follow-up work, we have resolved authorization and storage issues to fully release the updated corpus of MISP2021 Challenge to all researchers. The detailed description of the updated dataset is published in the second paper.
- The First Multimodal Information Based Speech Processing (MISP) Challenge: Data, Tasks, Baselines and Results
- Audio-Visual Speech Recognition in MISP2021 Challenge: Dataset Release and Deep Analysis
Please cite the following paper: @INPROCEEDINGS{chen2022misp, author={Chen, Hang and Zhou, Hengshun and Du, Jun and Lee, Chin-Hui and Chen, Jingdong and Watanabe, Shinji and Siniscalchi, Sabato Marco and Scharenborg, Odette and Liu, Di-Yuan and Yin, Bao-Cai and Pan, Jia and Gao, Jian-Qing and Liu, Cong}, booktitle={Proc. ICASSP 2022}, title={The First Multimodal Information Based Speech Processing (MISP) Challenge: Data, Tasks, Baselines and Results}, year={2022}}
Please cite the following paper: @INPROCEEDINGS{2022misptask2, author={Chen, Hang and Du, Jun and Dai, Yusheng and Lee, Chin-Hui and Siniscalchi, Sabato Marco and Watanabe, Shinji and Scharenborg, Odette and Chen, Jingdong and Yin, Bao-Cai and Pan, jia}, booktitle={Proc. INTERSPEECH 2022}, title={Audio-Visual Speech Recognition in MISP2021 Challenge: Dataset Release and Deep Analysis}, year={2022}}
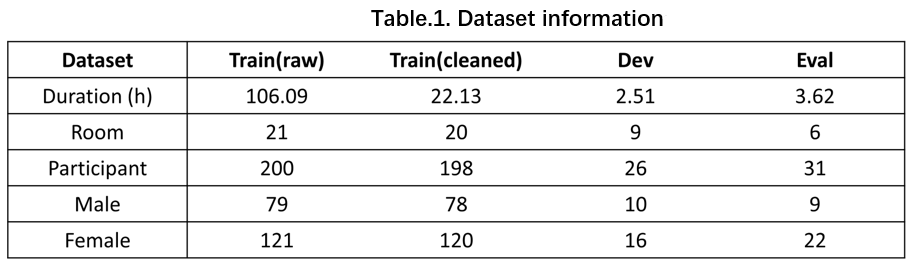
In the MISP 2022 challenge, we release a new development set and a new evaluation set, which has no duplicate speakers compared with other sets.
Since the previous two MISP challenges did not attract front-end speech processing systems, participants can directly use the raw data. However, this year, for the AVTSE task, clean reference speech in training set is required for model training. Due to the possibility of huge noise interference or unclear speech in part of the original near-field audio, we should conduct data cleansing on the training set based on the MISP 2022 dataset. Firstly, we divide the near-field speech into several segments based on timestamps, each containing only one speaker. Meanwhile, we preserve 5% of silence at the beginning and end of each segment (with a maximum duration of 4 seconds). Then the deep noise suppression mean opinion score (DNSMOS) is used to select segments with high speech quality, a non-intrusive speech quality metric t0 evaluate audio without reference to clean speech. We select the overall quality (OVRL) metric in DNSMOS, as it provides a comprehensive assessment of audio and background noise quality. We screen a total of 22.13 hours of speech segments with high OVRL scores in training set. We will provide a list and timestamps of the audio we have filtered. Participants can directly use them or utilize different methods to filter the data.
Due to the differences in crystal clocks of recording devices, there may be misalignment between near-field and far-field audio. Therefore, for the AVTSE task, we recommend that participants use the near-field audio to simulate the far-field audio and use the near-field audio as labels to train the model, or directly use far-field data for joint training with the back-end ASR model. We will provide a data simulation script that allows participants to utilize the screened near-field speech to simulate far-field scenarios easily. This script can generate reverbs based on room and device information and add noise with different signal-to-noise ratios (SNRs) to the speech segment, generating 6-channel far-field audio data. It is worth noting that this simulation method is not unique, and participants can design other simulation methods themselves.
The development set will use the audio data in development set of MISP 2022 challenge. The evaluation set will add some new sessions to the evaluation set of MISP 2022, which focus on female dialogue scenarios. Our research has revealed that distinguishing speaker voices in these female dialogue scenarios is more challenging, thus increasing the difficulty level for participants. In the development and evaluation sets, we will only provide the far-field audio and the middle-field video.
The data have been split into training, development, and evaluation sets as follows (evaluation set will be released later).
Audio
All audio data are distributed as WAV files with a sampling rate of 16 kHz. Each session consists of the recordings made by the far-field linear microphone array with 6 microphones, the middle-field linear microphone array with 2 microphones and the near-field high-fidelity microphones worn by each participant. These WAV files are named as follows: Far-field array microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Far_< Channel ID >.wav Middle-field array microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Middle_< Channel ID >.wav Near-field high-fidelity microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Near_< Speaker ID >.wav
Video
All video data are distributed as MP4 files with a frame rate of 25 fps. Each session consists of the recordings made by the far-field wide-angle camera and the middle-field high-definition cameras worn by each participant. These MP4 files are named as follows: Far-field wide-angle camera (1080p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Far.mp4 Middle-field high-definition camera (720p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Middle_< Speaker ID >.mp4
In addition, we will provide the detection results of face and lip. It includes the position of each speaker's face and lips in each frame of the video. Participants can choose whether to use this information.
In order to cover the real scene comprehensively and evenly, we designed the following recording configuration by controlling variables as in Table 1.
| Config ID | Time | Content | Light | TV | Group | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | Day | Wake word & Similar words | off | on | 1 | ||||||
| 01 | Talk freely | off | on | 1 | |||||||
| 02 | on | on | 1 | ||||||||
| 03 | off | off | 2 | ||||||||
| 04 | on | off | 2 | ||||||||
| 05 | off | on | 2 | ||||||||
| 06 | on | on | 2 | ||||||||
| 07 | on | off | 1 | ||||||||
| 08 | off | off | 1 | ||||||||
| 09 | Night | on | on | 1 | |||||||
| 10 | on | off | 2 | ||||||||
| 11 | on | on | 2 | ||||||||
| 12 | on | off | 1 | ||||||||
| Tab.2. Configuration | |||||||||||
"Time" refers to the recording time, the value is day or night. "Content" refers to the speaking content. We also recorded some data only containing wake-up/similar word to support audio-visual voice wake-up task. "Light" refers to turning on/off the light. "TV" refers to turning on/off the TV. "Group" refers to how much groups of participants in a conversation. By observing the real conversations these were taking place in real living room, we found that the participants would be divided into several groups to discuss different topics. Compared with all participants discussing the same topic, grouping would result in higher overlap ratios. We found that average speech overlap ratios of 𝐺𝑟𝑜𝑢𝑝 = 1 and 𝐺𝑟𝑜𝑢𝑝 = 2 are 10%~20% and 50%~70%, respectively. And the number of groups greater than 3 is very rare when the number of participants is no more than 6.