
Track1 Datasets
There isn’t duplicate speaker and room in training, development test and evaluation test sets.For training and development sets, the released video includes the far scenario and the middle scenario while the released audio includes the far scenario, the middle scenario and the near scenario. But for the evaluation set, we only release the video in far scenario and the audio in far scenario during the challenge.
The release of the evaluation set will use the same directory structure and file name rules as the development set. We will provide an oracle speech segmentation timestamp file with each line of content < start_time > < end_time > speech. Each line of the final submitted RTTM file is SPEAKER < Session_ID > 1 < start_time > < duration_time > NA NA
Directory Structure
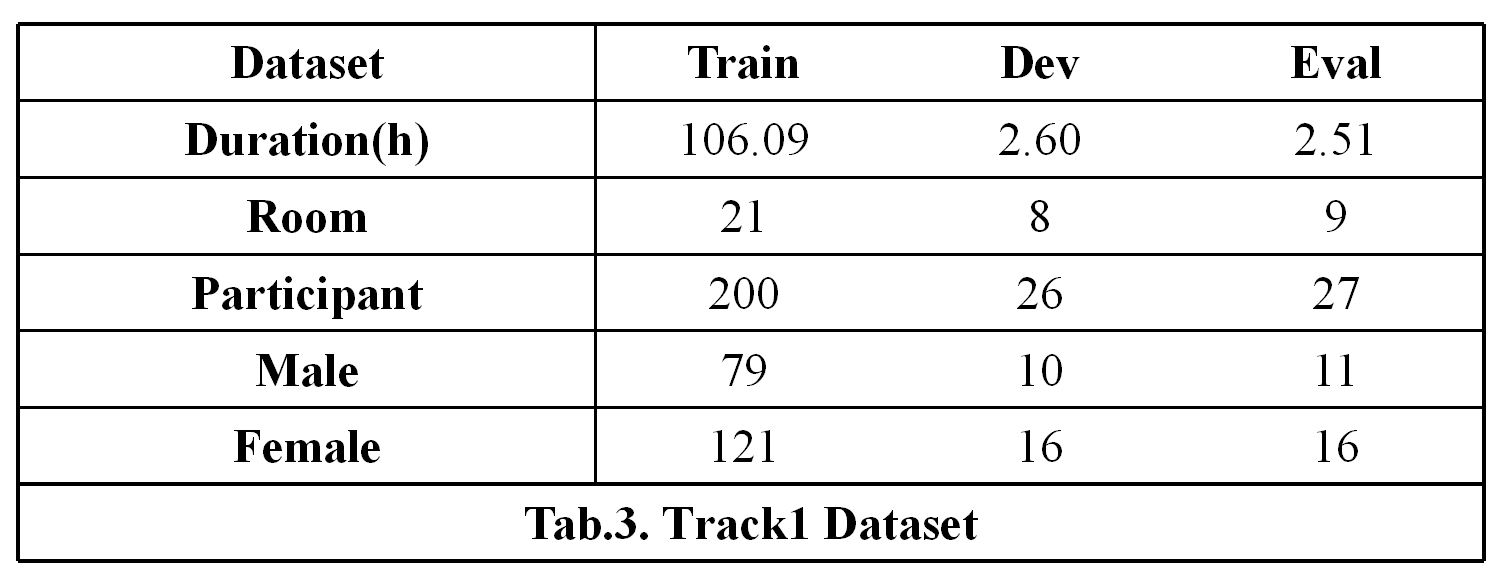
We plan to release an audio-visual wake word spotting dataset collected in home TV scenarios. The recording scenes can refer to Fig. 1. The wake word is “Xiao T Xiao T”. There are more than 300 speakers. The dataset’s accent is Mandarin and all data were collected in more than 30 real rooms. A sample will be taken as a positive sample if the wake word is included, otherwise it will be regarded as a negative sample. For each sample, at most one wake word is included. For the duration, different scenarios data (i.e. far, middle, and near field) are calculated separately. The statistics of the dataset are shown in Tab.1 above.

The data was divided into three subsets: Training, Development, Evaluation. Dataset split follows speaker and room independence, i.e. no speaker and room are repeated among the three splits. The audio data, video data follow the directory structure shown in Tab.2. Each positive/negative directory has subdirectories for audio/video. Each audio/video directory has subdirectories for training, development and evaluation sets. Each train/dev/ directory has subdirectories for far, middle, and near field recording devices in the audio directory. Each train/dev/ directory has subdirectories for far and middle field recording devices in the video directory. In addition, we will provide some noise data.
Audio
Each audio sample is stored in a single-channel 16-bit stream with a sampling rate of 16kHz. The WAV files are named as follows: Far-field audio: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >_Far_< Speaker ID >_< Channel ID >_< Segment ID 1 >_< Segment ID 2 >.wav Middle-field audio: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >_Middle_< Speaker ID >_< Channel ID >_< Segment ID 1>_< Segment ID 2 >.wav Near-field audio: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >_Near_< Speaker ID >_< Segment ID 1 >_< Segment ID 2 >.wav Here, < Segment ID 1 > and < Segment ID 2 > represent the start and the end time points of utterance segmentation in original sample respectively, which can be used to distinguish different examples.
Video
All video data are distributed as MP4 files with a frame rate of 25 fps. Each session consists of the recordings made by the far-field wide-angle camera and the middle-field high-definition cameras worn by each participant. These MP4 files are named as follows: Far-field wide-angle camera (1080p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >_Far_< Speaker ID >_< Segment ID 1 >_< Segment ID 2 >.mp4 Middle-field high-definition camera (720p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >_Middle_< Speaker ID >_< Segment ID 1 >_< Segment ID 2 >.mp4