

Task2 Instructions
Evaluation
In this Challenge, we adopt Chinese Character Error Rate (CCER) as an official metric for our ranking. CCER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform the recognition output into the ground truth text. It is represented with this formula:
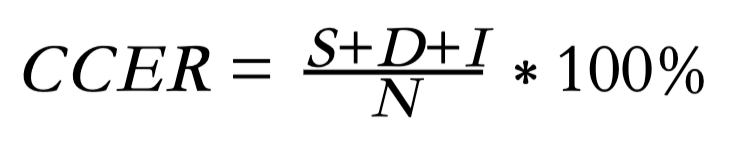
For training and development test sets, we will prepare the scoring script which will be released together with the baseline. For the evaluation test set, the participant should submit a text file to the Kaggle platform which contains recognition results for all utterances. And CCER will be calculated and updated in the leaderboard. Each line of the file should be in the form as < Utterance ID > < Chinese characters sequence >. Utterance IDs will be provided by the official.
Can I use extra audio/video/text data?
External text and audio are not allowed to be used during the language model training and the acoustic model training. But use of external slient video data is allowed in the pretrained model training under the following conditions:
- The used external resource is clearly referenced and freely accessible to any other research group in the world. External data refers to public datasets or trained models. The data must be public and freely available before 3rd of February 2022.
- The list of external data sources used in training must be clearly indicated in the technical report.
- Participants inform the organizers in advance about such data sources, so that all competitors know about them and have an equal opportunity to use them. Please send an email to the task coordinators; we will update the list of external datasets on the webpage accordingly. Once the evaluation set is published, the list of allowed external data resources is locked (no further external sources allowed).
Which information can I use?
You can use the following annotations for training, development, and evaluation:
- the corresponding room sizes
- the corresponding configuration labels (as shown in Tab.1)
- the corresponding speaker labels
- the start and end times of all utterances
For training and development, you can use the full-length recordings of all recording devices. For evaluation, you are allowed to use for a given utterance the full-length recordings of far-field devices (both the linear 6 microphones array and the wide-angle camera) for that session.
Which information shall I not use?
Manual modification of the data or the annotations (e.g., manual refinement of the utterance start and end times) is forbidden. All parameters should be tuned on the training set or the development set. Modifications of the development set are allowed, provided that its size remains unchanged and these modifications do not induce the risk of inadvertently biasing the development set toward the particular speakers or acoustic conditions in the evaluation set. For instance, enhancing the signals, applying “unbiased” transformations or automatically refining the utterance start and end times is allowed. Augmenting the development set by generating simulated data, applying biased signal transformations (e.g., systematically increasing intensity/pitch), or selecting a subset of the development set is forbidden. In case of doubt, please ask us ahead of the submission deadline.
Can I use a recognizer or overall system different from those in the official baseline pipeline?
Again, you are entirely free in the development of your system.
In particular, you can:
- include a single-channel or multi-channel audio enhancement front-end
- include a video pre-processing
- use other acoustic features and visual features
- modify the acoustic/visual/acoustic-visual model architecture or the training criterion
- modify the lexicon and the language model
- use any rescoring technique
Which results should I report?
For every tested system, you should report CCER in both development and evaluation sets (%).