

Task1 Instructions
Evaluation
This is a classification problem. ‘1’ indicates that the current sample contains the wake-up word, and ‘0’ indicates the opposite. We use false reject rate (FRR) and false alarm rate (FAR) on evaluation set as the criterion of the WWS performance. Suppose the test set consists of Nwake examples with wake word and Nnon-wake examples without wake word, FRR and FAR are defined as follows:
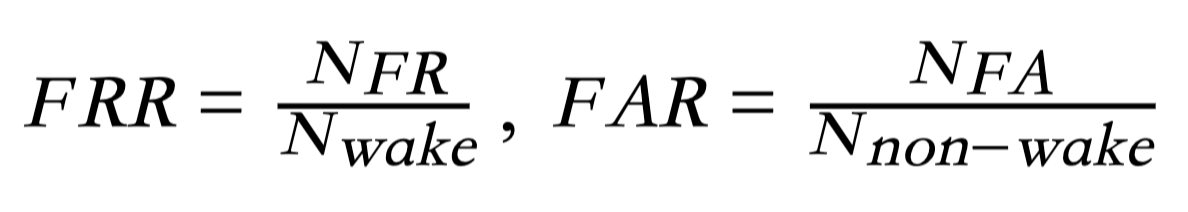
where NFR denotes the number of examples including wake-up word but the WWS system gives a negative decision. NFA is the number of examples without wake-up word but the WWS system gives a positive decision. The final score of KWS is defined as:
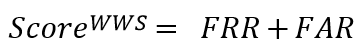
FRR and FAR are calculated on all samples in evaluation set and the final rank is ScoreWWS. The system has lower ScoreWWS will be ranked higher. For training and development sets, we will prepare the scoring script which will be released together with the baseline. For the evaluation test set, the participant should submit a text file to the Kaggle platform which contains classification results for all utterances. And ScoreWWS will be calculated and updated in the leaderboard. Each line of the file should be in the form as < Utterance ID > < 0 or 1 >. Utterance IDs will be provided by the official. ‘0’ and ‘1’ representthe prediction results of the current sample.
Can I use extra audio/video data?
The use of any external audio data that is not provided by organizers (except for RIR) is strictly prohibited. But use of external slient video data is allowed in the pretrained model training under the following conditions:
- The used external resource is clearly referenced and freely accessible to any other research group in the world. External data refers to public datasets or trained models. The data must be public and freely available before the end of the challenge.
- The list of external data sources used in training must be clearly indicated in the technical report.
- Participants inform the organizers in advance about such data sources, so that all competitors know about them and have an equal opportunity to use them. Please send an email to the task coordinators; we will update the list of external datasets on the web page accordingly. Once the evaluation set is published, the list of allowed external data resources is locked (no further external sources allowed).
What can I use?
It is allowed to use the development set to train the WWS model. The exploration of different data augmentation and simulation methods are encouraged to allow the participants to train their models better. In addition, you can use the following annotations for training, development:
- the corresponding room sizes
- the corresponding speaker labels
Which information shall I not use?
Manual modification of the data is forbidden. All parameters should be tuned on the training set or the development set. Modifications of the development set are allowed, provided that its size remains unchanged and these modifications do not induce the risk of inadvertently biasing the development set toward the particular speakers or acoustic conditions in the evaluation set. For instance, enhancing the signals, applying “unbiased” transformations or automatically refining the utterance start and end times is allowed. Augmenting the development set by applying biased signal transformations (e.g., systematically increasing intensity/pitch), or selecting a subset of the development set is forbidden. In case of doubt, please ask us ahead of the submission deadline.
There is also no limitation on WWS model structure and model training technology used by participants. Again, you are entirely free in the development of your system. In particular, you can:
- use other video pre-processing methods
- use other acoustic features and visual features
- modify the audio/visual/audio-visual model architecture or the training criterion
Which results should I report?
For every tested system, you should report ScoreWWS in both development and evaluation sets.