
Track1 AVSD Baseline
For details, please refer to Github link
Data preparation
- Speech enhancement
- Lip ROI extraction
Weighted Prediction Error(WPE) dereverberation is used to reduce the reverberations of speech signals. The algorithms is implemented with open-source toolkit, nara_wpe
In the dataset, we provide the position detection results of the face and lips, which can be used to extract the ROI of the face or lips (only the lips are used here). The extracted lip ROI size is 96 × 96 (W × H) .
Visual embedding module
The visual embedding module is illustrated in the top row of Fig.1. On the basis of the original lipreading model, we add three conformer blocks with 256 encoder dims, 4 attention heads, 32 conv kernel size and a 256-cell BLSTM to compute the visual embedding for speakers. The whole network can be regarded as visual voice activity detection (V-VAD) module. After pre-training the visual network as a V-VAD task, V-embeddings are equipped with capability that represent the states of speaking or silent. By feeding the embedding into the fully connected layers, we can get the probability of whether a speaker speaks in each frame. Combining the results of each speaker, we will get the initial diarization results.
Audio embedding module
We firstly use the NARA-WPE method to dereverberate the original audio signals. Then, We extracted 40-dimensional FBANKs with 25 ms frame length and 10 ms frame shift. We extract the audio embedding from FBANKS through 4 layers 2D CNN. Then, a fully connected layer projects high dimensional CNNs output to low dimensional A-embeddings. Unlike visual network, we don’t pre-train audio network on any other tasks and directly optimize it with audio-visual decoding network.
Speaker embedding module
To reduce the impact of the unreliable visual embedding, we use 100-dimensional i-vector extractor which was trained on Cn-celeb to get the i-vectors as the speaker embedding. We compute i-vectors through the oracle labels for each speaker in the training stage. And in the inference stage, we compute i-vectors through the initial diarization results from the visual embedding extraction module.
Decoder module
We firstly repeat the three embeddings for different times to solve the problem of different frame shift between audio and video. Then, we combine them to get the total embedding. In the decoding block, we use 2-layer BLSTM with projection to further extract the features. Finally, we use a 1-layer BLSTM with projection and the fully connected layer to get the speech or non-speech probabilities for each speaker respectively. All of BLSTM layers contained 896 cells. In the post-processing stage, we first perform thresholding with the probabilities to produce a preliminary result and adopt the same approaches in previous work. Furthermore, DOVER-Lap is used to fuse the results of 6-channels audio.
Decoder module
We firstly repeat the three embeddings for different times to solve the problem of different frame shift between audio and video. Then, we combine them to get the total embedding. In the decoding block, we use 2-layer BLSTM with projection to further extract the features. Finally, we use a 1-layer BLSTM with projection and the fully connected layer to get the speech or non-speech probabilities for each speaker respectively. All of BLSTM layers contained 896 cells. In the post-processing stage, we first perform thresholding with the probabilities to produce a preliminary result and adopt the same approaches in previous work. Furthermore, DOVER-Lap is used to fuse the results of 6-channels audio.
Training process
First, we use the parameters of the pre-trained lipreading and train the V-VAD model with a learning rate of 10-4. Then, we freeze the visual network parameters and train the audio network and audio-visual decoding block on synchronized middle-field audio and video with a learning rate of 10−4. Finally,we unfreeze the visual network parameters and train the whole network jointly on synchronized middle-field audio and video with a learning rate of 10−5.
Baseline Results
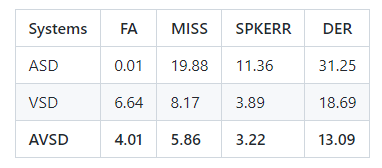
We use Diarization error rate (DER) as the evaluation index. The above results are measured on the far-field audio and video. For the ASD system, we use the VBx method. For the VSD system, we use the result from the visual embedding module. And the AVSD system is our method. At the same time, this AVSD result also serves as the baseline result of the MISP2022 Challenge Track 1 in development set. The baseline results of the evaluation set will be published together with the data according to the schedule.
Quick start
- Add file execution permissions
- Data prepare
- Setting kaldi
- Pre-trained model
- Training
- Decoding
-
Kaldi
-
pytorch
-
Python Packages: nbformat argparse numpy tqdm opencv-python einops scipy prefetch_generator
chmod +x -R /export/corpus/exp/av_diarization/misp2022_baseline/track1_AVSD/ # (Your code path)
bash data_prepare.sh # (Please change your file path in the script. Note that WPE is not necessary for training set)
--- cmd.sh ---
export train_cmd=run.pl
export decode_cmd=run.pl
export cmd=run.pl
--- path.sh ---
export KALDI_ROOT=`pwd`/../../.. # Defining Kaldi root directory
#[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
Export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$KALDI_ROOT/tools/irstlm/bin/:$PWD:$PATH
[ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present -> Exit!" && exit 1
. $KALDI_ROOT/tools/config/common_path.sh
export LC_ALL=C
There are three pre-trained models.
The conformer_v_sd_2.model and av_diarization_3.model are the pre-trained models of visual embedding module and audio-visual module respectively. You can choose whether to download them. Specifically, if you do not want to conduct the training process but directly decode, you can download these two models.
Lipreading_LRW.pt is the pre-trained model of lipreading. The training process will use it. Therefore, if you want to conduct the training process, you must download this model.
conformer_v_sd_2.model
av_diarization_3.model
lipreading_LRW.pt
The link of Google drive is: https://drive.google.com/drive/folders/1kh40NNBW84kODM0PrWvYLwDCjuqpKqj7?usp=sharing
Please put the downloaded model into model/pretrained/
bash run.sh
# options:
--stage 1
# change the number to start from different training stage
Please change some file paths in the script to your own path.
If you have downloaded the pre-trained models, you can directly do the decoding process.
bash run.sh
# options:
--stage 5
# change the number to start from different training stage
(stage 5 ~ 9 are the decoding process using single channel audio; stage 10 ~ 11 are the decoding process fusing 6-channels audio)
The lip ROI and ivector of the training set will be used in the decoding process. So you need to use stage2 of data_prepare.sh to extract the lip ROI of the training set, and use stage 3 of run.sh to extract the ivector of the training set. We have prepared the ivector of the training set. You can directly use it.
Requirments
Citation
If you find this code useful in your research, please consider to cite the following papers: @inproceedings{he2022, title={End-to-End Audio-Visual Neural Speaker Diarization}, author={He, Mao-kui and Du, Jun and Lee, Chin-Hui}, booktitle={Proc. Interspeech 2022}, pages={1461--1465}, year={2022}}