Background
With the emergence of many speech-enable applications, the scenarios (e.g., home and meeting) are becoming increasingly challenging due to the factors of adverse acoustic environments (far-field audio, background noises, and reverberations) and conversational multi-speaker interactions with a large portion of speech overlaps. The state-of-the-art speech processing techniques based on the single audio modality encounter the performance bottlenecks, e.g., yielding the word error rate of about 40% in CHiME-6 dinner party scenario.
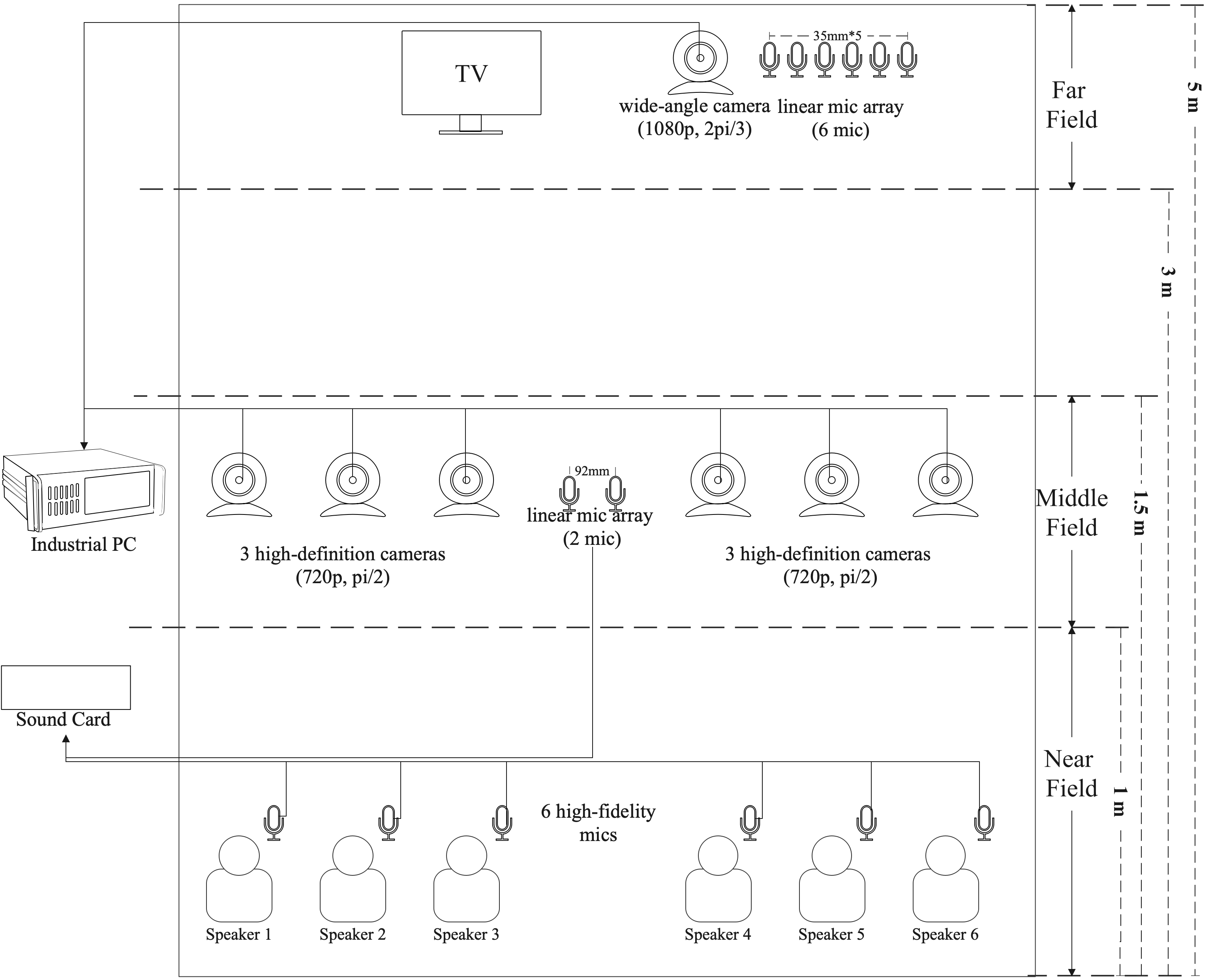
Inspired by the finding that visual cues can help human speech perception, the multimodal information based speech processing (MISP) challenge aims to extend the application of signal processing technology in specific scenarios, using audio and video data. MISP challenge targets the home TV scenario, where several people are chatting in Chinese while watching TV in the living room. As the new features, the carefully selected far-field/mid-field/near-field microphone arrays and cameras are arranged to collect both audio and video data, respectively. Also the time synchronizations among different microphone arrays and video cameras are well designed for conducting the research on the multi-modality fusion.
With the success of MISP 2021 challenge, some advanced Audio-Visual Speech Recognition (AVSR) systems have been proposed. However, these systems use the oracle speaker diarization results, which greatly limits its scope in real-world applications. For the MISP2022 challenge, we target the problem of Audio-Visual Speaker Diarization (AVSD), and Audio-Visual Diarization and Recognition (AVDR) in the home-tv scenarios. Specifically, the AVDR is an extended task from AVSR, replacing oracle speaker diarization results with AVSD results.
How to leverage on both audio and video data to improve the environmental robustness is quite interesting in this challenge. The researchers from both academia and industry are warmly welcome to work on our two audio-visual tracks (with details as below) for promoting the research of speech processing using multimodal information to cross the practical threshold of realistic applications in challenging scenarios. All approaches are encouraged, whether they are emerging or established, and whether they rely on signal processing or machine learning.
The intellectual property (IP) is not transferred to the challenge organizers, i.e., if code is shared/submitted, the participants remain the owners of their code.