
In the MISP 2021 challenge, we released a large multi-microphone conversational audio-visual corpus. This corpus focus on the home-TV scenarios: 2-6 people communicating each other with TV noise in the background. The detailed scenario and recording setup can be found in the first paper. In the follow-up work, we have resolved authorization and storage issues to fully release the updated corpus of MISP2021 Challenge to all researchers. The detailed description of the updated dataset is published in the second paper.
- The First Multimodal Information Based Speech Processing (MISP) Challenge: Data, Tasks, Baselines and Results
- Audio-Visual Speech Recognition in MISP2021 Challenge: Dataset Release and Deep Analysis
Please cite the following paper: @INPROCEEDINGS{chen2022misp, author={Chen, Hang and Zhou, Hengshun and Du, Jun and Lee, Chin-Hui and Chen, Jingdong and Watanabe, Shinji and Siniscalchi, Sabato Marco and Scharenborg, Odette and Liu, Di-Yuan and Yin, Bao-Cai and Pan, Jia and Gao, Jian-Qing and Liu, Cong}, booktitle={Proc. ICASSP 2022}, title={The First Multimodal Information Based Speech Processing (MISP) Challenge: Data, Tasks, Baselines and Results}, year={2022}}
Please cite the following paper: @INPROCEEDINGS{2022misptask2, author={Chen, Hang and Du, Jun and Dai, Yusheng and Lee, Chin-Hui and Siniscalchi, Sabato Marco and Watanabe, Shinji and Scharenborg, Odette and Chen, Jingdong and Yin, Bao-Cai and Pan, jia}, booktitle={Proc. INTERSPEECH 2022}, title={Audio-Visual Speech Recognition in MISP2021 Challenge: Dataset Release and Deep Analysis}, year={2022}}
For the MISP 2022 challenge, our training set is the same as that mentioned in the second paper, and our new development set is selected from the development and evaluation sets of the MISP 2021 challenge. In addition, we will also release a new evaluation set, which has no duplicate speakers compared with other sets.
The challenge uses the MISP2022 dataset which contains 100+ hours of audio-visual data. The dataset includes 320+ sessions. Each session consists of a about 20-minutes discussion. The reason why we select an about 20-min duration rather than a longer recording for a session is that we want to alleviate the clock drift problem for synchronizing multiple devices.
The data have been split into training, development, and evaluation sets as follows (evaluation set will be released later).
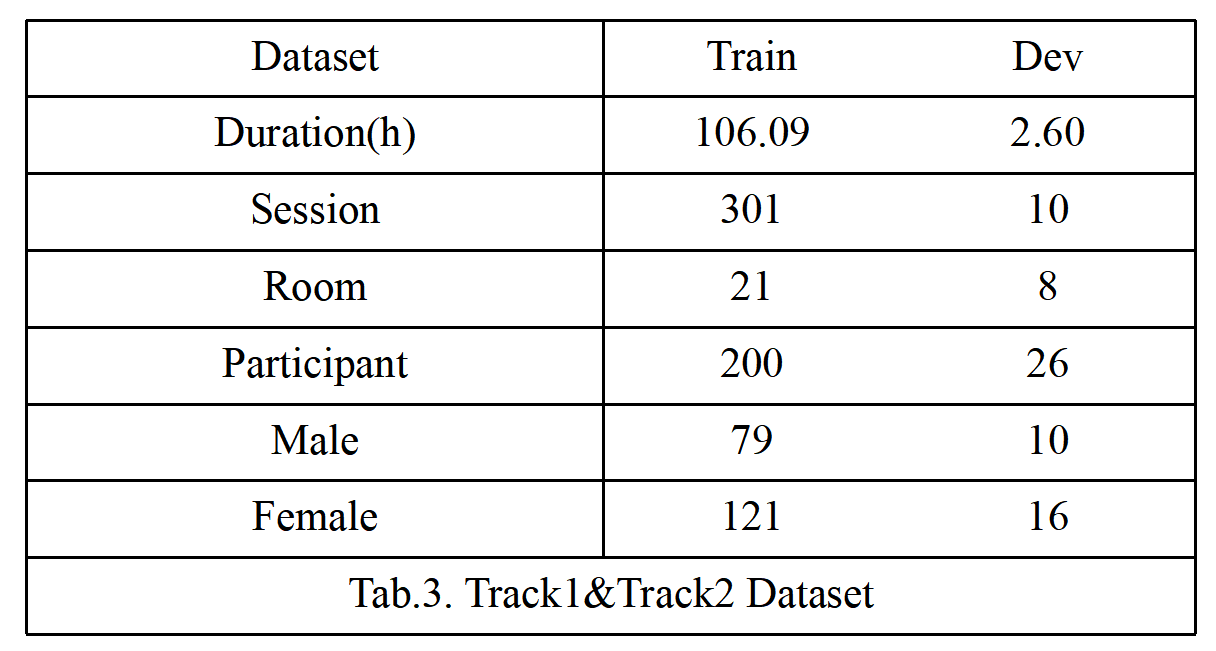
For training set, the released video includes the far scenario and the middle scenario while the released audio includes the far scenario, the middle scenario and the near scenario. But for the development and evaluation sets, we only release the video in far scenario and the audio in far scenario during the challenge.
The release of the evaluation set will use the same directory structure and file name rules as the development set.
For track 1, we will provide the oracle RTTM files in training and development sets. The RTTM files are named as < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >.rttm
Each line of the RTTM file is:
SPEAKER < Session_ID > 1 < start_time > < duration_time > NA NA < speaker_ID > NA NA
Participants need to submit the RTTM file in the same form, and the Session_ID of the result file must be exactly the same as the official file.
For track 2, we will provide the oracle RTTM files that are the same as track 1. In addition, we will provide the transcription files in training and development sets. The transcriptions are provided in TextGrid format for each speaker in each session. We use speech signal recorded by the near-field high-fidelity microphone to manual transcription. After manual rechecking, the transcription accuracy rate is as high as 99% or more. The TextGrid files are named as < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Near_< Speaker ID >.TextGrid
The TextGrid file includes the following pieces of information for each utterance:
- Start time ("start_time")
- End time ("end_time")
- Transcription ("Chinese characters")
Each line of the final submitted text file is < speaker ID >_< session ID > < utterance > , and the session_ID of the result file must be exactly the same as the official file.
For both track 1 and track 2, we also provide the oracle speech segmentation timestamp files in training, development, and evaluation sets. These files are named as < Room ID >_< Speakers IDs >_< Configuration ID >_< Index >.lab
And each line of the timestamp file is:
< start_time > < end_time > speech
Directory Structure
There is a pdf file in the top-level directory, called data-specification.pdf, which describes the introduction of the data set. There are two txt files in the “doc” folder, speaker_info.txt describes the gender and age range of every speaker, and room_info.txt describes the size of every room.
The audio data, video data and other files follow this directory structure.

Audio
All audio data are distributed as WAV files with a sampling rate of 16 kHz. Each session consists of the recordings made by the far-field linear microphone array with 6 microphones, the middle-field linear microphone array with 2 microphones and the near-field high-fidelity microphones worn by each participant. These WAV files are named as follows: Far-field array microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Far_< Channel ID >.wav Middle-field array microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Middle_< Channel ID >.wav Near-field high-fidelity microphone: < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Near_< Speaker ID >.wav
Video
All video data are distributed as MP4 files with a frame rate of 25 fps. Each session consists of the recordings made by the far-field wide-angle camera and the middle-field high-definition cameras worn by each participant. These MP4 files are named as follows: Far-field wide-angle camera (1080p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Far.mp4 Middle-field high-definition camera (720p): < Room ID >_< Speakers IDs >_< Configuration ID >_< Index > _Middle_< Speaker ID >.mp4
In addition, we will provide the detection results of face and lip. It includes the position of each speaker's face and lips in each frame of the video. Participants can choose whether to use this information.
In order to cover the real scene comprehensively and evenly, we designed the following recording configuration by controlling variables as in Table 1.
| Config ID | Time | Content | Light | TV | Group | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 00 | Day | Wake word & Similar words | off | on | 1 | ||||||
| 01 | Talk freely | off | on | 1 | |||||||
| 02 | on | on | 1 | ||||||||
| 03 | off | off | 2 | ||||||||
| 04 | on | off | 2 | ||||||||
| 05 | off | on | 2 | ||||||||
| 06 | on | on | 2 | ||||||||
| 07 | on | off | 1 | ||||||||
| 08 | off | off | 1 | ||||||||
| 09 | Night | on | on | 1 | |||||||
| 10 | on | off | 2 | ||||||||
| 11 | on | on | 2 | ||||||||
| 12 | on | off | 1 | ||||||||
| Tab.5. Configuration | |||||||||||
"Time" refers to the recording time, the value is day or night. "Content" refers to the speaking content. We also recorded some data only containing wake-up/similar word to support audio-visual voice wake-up task. "Light" refers to turning on/off the light. "TV" refers to turning on/off the TV. "Group" refers to how much groups of participants in a conversation. By observing the real conversations these were taking place in real living room, we found that the participants would be divided into several groups to discuss different topics. Compared with all participants discussing the same topic, grouping would result in higher overlap ratios. We found that average speech overlap ratios of 𝐺𝑟𝑜𝑢𝑝 = 1 and 𝐺𝑟𝑜𝑢𝑝 = 2 are 10%~20% and 50%~70%, respectively. And the number of groups greater than 3 is very rare when the number of participants is no more than 6.