
Task 1: Wake Word Lipreading
This is a classification problem, while '1' indicates that the current sample contains the wake-up word, and '0' indicates the opposite. We use false reject rate (FRR) and false alarm rate (FAR) on the evaluation set as the criterion of the WWS performance. Suppose the test set consists of Nwake examples with wake-up word and Nnon-wake examples without wake-up word, FRR and FAR are defined as follows:
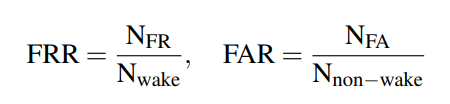
where NFR denotes the number of examples including the wake-up word but the WWS system gives a negative decision. NFA is the number of examples without the wake-up word but the WWS system gives a positive decision. The final score of WWS is defined as:
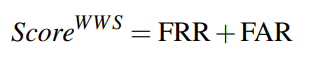
FRR and FAR are calculated on all samples in the evaluation set, and the final rank is ScoreWWS. The system with a lower ScoreWWS will be ranked higher.
Task 2: Target Speaker Lipreading
In this Challenge, we adopt the Chinese Character Error Rate (CER) as an official metric for our ranking. CER calculation is based on the concept of Levenshtein distance, where we count the minimum number of character-level operations required to transform the recognition output into the ground truth text. It is represented with this formula:
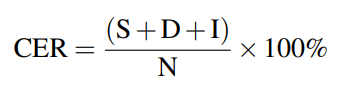
Where S is the number of substitutions, D is the number of deletions, I is the number of insertions, and N is the number of characters in ground truth. The lower CER value (with 0 being a perfect score), the better the recognition performance. Due to multi-speaker interaction in our scenario, there are the speech segments with multiple speakers talking simultaneously. For such speech overlap segments, we calculate all the S/I/D errors based on the recognition results and the ground truth for each speaker based on the oracle speaker diarization results.