
Task 1: Wake Word Lipreading
We use the far-field videos released in the MISP 2021 Task 1, collected in home TV scenarios. The wake-up word is “Xiao T Xiao T”. There are 338 speakers. The dataset’s accent is Mandarin; all data were collected in 33 real rooms. A sample will be taken as a positive sample if the wake-up word is included, otherwise, it will be regarded as a negative sample. For each sample, at most one wake-up word is included. The statistics of the dataset are shown in Table 1.
| Dataset | Train | Dev | Eval | Total | ||||
|---|---|---|---|---|---|---|---|---|
| Positive | Negative | Positive | Negative | Positive | Negative | Positive | Negative | |
| Duration (h) | 1.83 | 35.96 | 0.16 | 0.76 | 0.56 | 2.34 | 2.55 | 39.06 |
| Session | 88 | 8 | 27 | 148 | ||||
| Room | 25 | 5 | 8 | 38 | ||||
| Participant | 253 | 28 | 47 | 328 | ||||
| Male | 79 | 9 | 27 | 115 | ||||
| Female | 174 | 19 | 20 | 213 | ||||
On one side, our wake word spotting dataset encompasses over 30 rooms and 300 speakers, showcasing diverse rooms and different speakers, thus enhancing the complexity and diversity of our dataset. Conversely, this dataset includes words that share similar lip shapes with the wake-up words, amplifying the difficulty.
Task 2: Target Speaker Lipreading
We utilize the far-field videos from the training and development sets of MISP2021 AVSR dataset to construct the training set for Task 2. The development and evaluation sets contain 6 males and 6 females, whose videos are also included in the training set. Each speaker possesses approximately 30 minutes of data. Two-thirds of each person's data make up the development set, while the remaining data make up the evaluation set. The statistics of the dataset are shown in Table 2.
| Dataset | Train | Dev | Eval | Total |
|---|---|---|---|---|
| Duration (h) | 110.95 | 4.50 | 2.41 | 117.86 |
| Session | 339 | 12 | 6 | 357 |
| Participant | 229 | 12 | 12 | 224 |
| Male | 90 | 6 | 6 | 91 |
| Female | 139 | 6 | 6 | 133 |
To cover the real scene comprehensively and evenly, we designed the following recording configuration by controlling variables as in Table 3. ‘Time’ refers to the recording time, the value is day or night. ‘Content’ refers to the speaking content. We also recorded some data only containing wake-up/similar words to support the audio-visual wake-word spotting task. ‘Light’ refers to turning on/off the light. ‘TV’ refers to turning on/off the TV. ‘Group’ refers to how many groups of participants are in a conversation.
| Config ID | Time | Content | Light | TV | Group |
|---|---|---|---|---|---|
| 01 | Day | Talk freely | off | on | 1 |
| 02 | on | on | 1 | ||
| 03 | off | off | 2 | ||
| 04 | on | off | 2 | ||
| 05 | off | on | 2 | ||
| 06 | on | on | 2 | ||
| 07 | on | off | 1 | ||
| 08 | off | off | 1 | ||
| 09 | Night | on | on | 1 | |
| 10 | on | off | 2 | ||
| 11 | on | on | 2 | ||
| 12 | on | off | 1 |
By observing the real conversations that were taking place in the real living room, we found that the participants would be divided into several groups to discuss different topics. Compared with all participants discussing the same topic, grouping would result in higher overlap ratios. We found that the average speech overlap ratios of Group = 1 and Group = 2 are 10% ~ 20% and 50% ~ 70%, respectively. The number of groups greater than 3 is very rare when the number of participants is no more than 6.
Scenario and Recording Setup
Figure 2 is a schematic diagram, showing the recording scene with six participants. According to the distance between the device and the speaker, multiple recording devices were divided into 2 categories:
- Far devices: A wide-angle camera (1080p, 25 fps, 2pi/3), which is placed 3-5m away from the speaker. All participants appear in the camera, which brings speakers position information while reducing the resolution of the lip region of interest (ROI);
- Middle devices: $n$ high-definition cameras (720p, 25fps, pi/2), placed 0.8-1.5m away from the speaker, where n is the number of participants within this conversation. There is only the corresponding speaker in each camera, and the lip ROI is recorded clearly;
Various devices have resulted in inconsistent clocks. We address that from two aspects: synchronization devices, and manual post-processing.
- Synchronization devices: The clocks of near high-fidelity microphones while Vicando software, running on the industrial PC (MIC-770), is used to synchronize the clocks of all cameras.
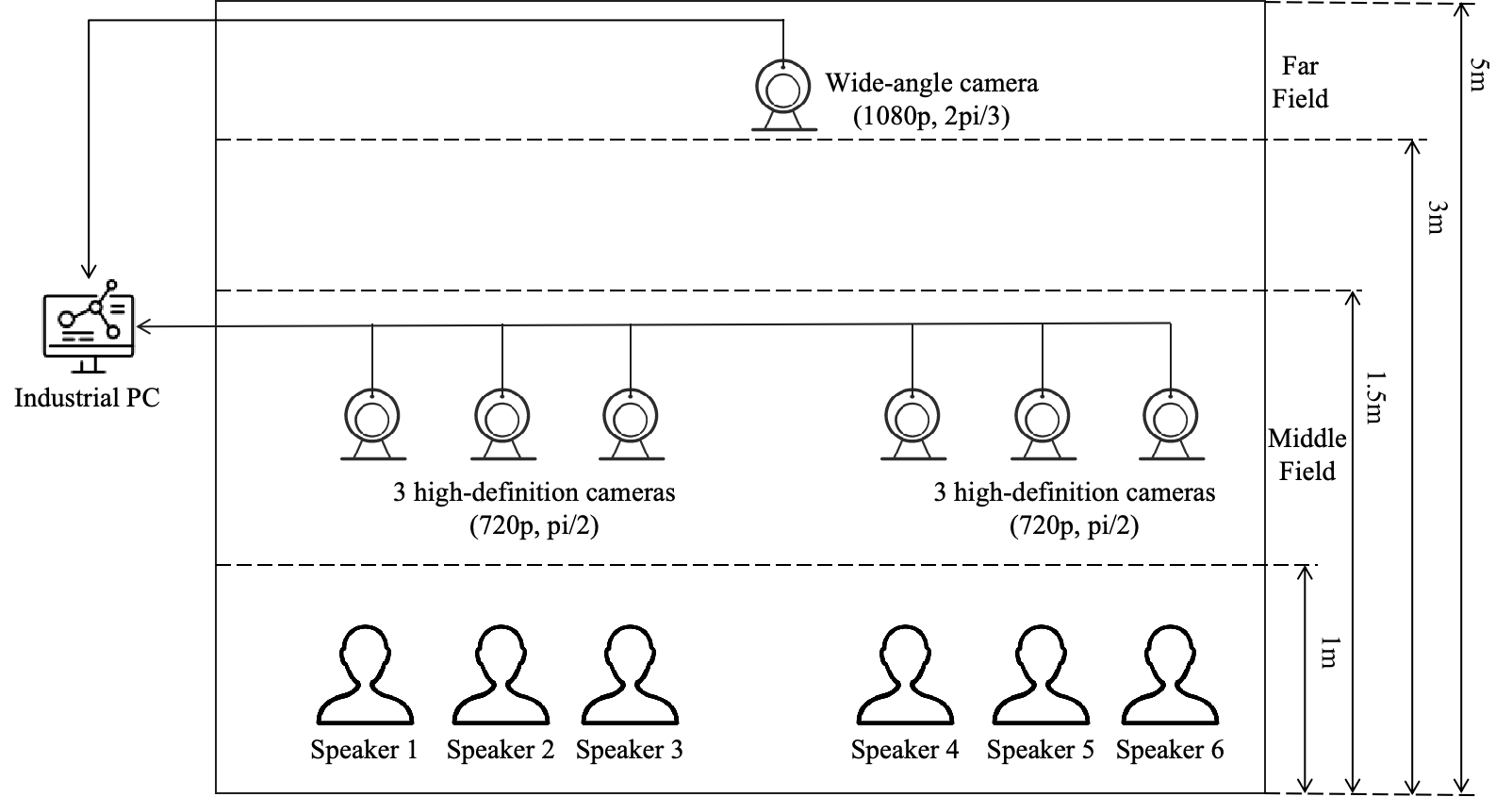
In the far field, a wide-angle camera will capture all speakers simultaneously, mirroring the most common scenario in real-life situations. All participants freely select topics and engage in unrestrained discourse in real home settings, resembling the most prevalent multi-speaker conversational scenarios in daily life. There still are some variables in the conversation that are taking place in the real living room, for example, the conversation is happening during the day or night. Specifically, by observing the real conversations in the real living room, we found that participants would be divided into several groups to discuss different topics. Compared with all participants discussing the same topic, grouping would result in higher overlap ratios. We control the above variables to cover the real scene comprehensively and evenly during the recording.